Recently (2022.1) Unity introduced LockBufferForWrite buffer type, and respective API functions:
Unity GraphicsBuffer.LockForWrite
The documentation states "The returned native array points directly to GPU memory if possible."
It made me curious, how close is this “directly” exactly?
Heaps in modern graphics API
To summarize, currently there are two sources of the data between CPU and GPU. It’s either RAM (Host) or VRAM (Device). If omit different swap methods etc.
On descrete GPUs, when the GPU will try to read RAM (Host Memory) the GPU manager will transfer the data from RAM to small temporary portion of video memory via PCI-E. Simillar happens when CPU will try to read VRAM.
So heap can be Host Local, or Device Local, regardless of the fact that both parties can usually access both of the heaps.
What’s the matter?
The exact heap you chose for your data should depend on the exact use case of that data.
For instance, imagine a texture: you read it once from your hard drive, upload it to the GPU, and then read it multiple times – possibly thousands or even millions of times per frame. (Rare Write, Often Read)
Conversely, consider per-draw data. If you want to draw 10,000 objects (not that unusual), you need to pass properties like color, scale, etc., which might change once or multiple times per frame (or per pass) but are read only once, at the moment of the Draw or Dispatch call (Often Write, Read Once)
For the first use case, a Device Local Non-Host Visible heap is usually used to indicate that your graphics code prefers optimized reading over writing in this region. You can upload data via a staging (Host Local + Device Visible) buffer. For example, copy data into RAM, allocate Device Local memory, then ask the GPU to transfer data from RAM to VRAM directly.
For the second use case, two different heaps can be used: Device Local + Host Visible or Host Local + Device Visible. The difference between them lies in the data’s locality. Both are good choices for per-draw temporary data. However, Device Local could also be read multiple times, making it a perfect choice for a third use case: Often Write, Often Read. An example would be a texture simulated on the CPU.
What does Unity offer?
A GraphicsBuffer without the LockBufferForWrite flag will use a Device Local, Non-Host Visible buffer. When asked to upload data via GraphicsBuffer.SetData or CommandBuffer.SetData, Unity will first write your data to RAM (a staging buffer) and then ask the GPU to transfer it via PCI-E. (Good for Rare Write, Often Read)
Investigating Unity’s code reveals that it uses D3D12_UPLOAD_HEAP (Host Local + Device Visible) when GraphicsBuffer.UsageFlags.LockBufferForWrite is requested. Thus, unless the driver applies specific optimizations (such as SAM on AMD), the memory will remain Host Local. This is not as close to the GPU as you might expect, but it’s still good for Often Write, Read Once, or handling huge amounts of data that won’t reside in GPU VRAM.
Ideally, Unity would use D3D12_HEAP_TYPE_GPU_UPLOAD instead, or give you the ability to choose to allocate the data from Device Local + Host Visible memory. However, this is still fairly new even in the D3D12 API.
Video cards with ReBAR (Resizable Base Address Register), such as the NVIDIA RTX 3000 series and higher, can make the entire VRAM Host Visible, making it ideal for comfortable data transfers. But ReBAR is relatively new, and even the RTX 2000 series doesn’t support it.
In Vulkan, there are other options: most cards (both AMD and NVIDIA), even those without claimed ReBAR support (like the NVIDIA GTX 980Ti), will still give you access to around 200MB of DeviceLocal+HostVisible memory. That’s usually enough to store all per-draw constants and double-buffer them. Trust me, you want that 🙂
So what should I use?
- For buffers that are written once or less times per frame but read multiple times, use a GraphicsBuffer without the LockBufferForWrite bit. You pay the cost of copying the data from your RAM to Unity’s allocated staging buffer (also in RAM) and then to the GPU via PCI-E, but the data will be read as quickly as possible.
- For the most efficient read once (per draw), use a GraphicsBuffer with the LockBufferForWrite bit. Preferable write it once per frame and double buffer it.
Futher reading:
AMD GPUOpen: Effective Use of the New D3D12_HEAP_TYPE_GPU_UPLOAD Really good article about new D3D12_HEAP_TYPE_GPU_UPLOAD heap, also touches the situation in Vulkan.
One more note about the AMD’s article:
There is yet another possibility: to have a memory pool located in video RAM but directly accessible for mapping to the CPU. This feature has existed for a long time, and it was known as Base Address Register (BAR). This special area of memory typically had only 256 MB.
Those 256MB typically exist even if the GPU doesn’t claim to support ReBAR (in fact, it can). As I mentioned, the NVIDIA GTX 980Ti or higher doesn’t officially support ReBAR, but these cards (both AMD and NVIDIA) expose around 200MB in memory. Also, AMD is known to optimize D3D12_HEAP_TYPE_UPLOAD to be truly DeviceLocal+HostVisible instead of HostLocal+DeviceVisible. I’m not sure whether NVIDIA does the same.
All Intel Arc cards seems to support ReBAR so whole memory is visible to the Host, at least in Vulkan.
NVIDIA’s article also shows how to detect if the upload heap was optimized to a Device Local heap (by measuring L2 Misses To System Memory
Forcing NVIDIA to use Device Local memory instead of Host Local
It’s always possible to replace the pointer in the GraphicsBuffer to an internal representation (aka ID3D12Buffer*) in Unity. Unfortunately, I can’t share publicly how exactly you can do that, but it’s not a rocket science, and I can do that for you if you need.
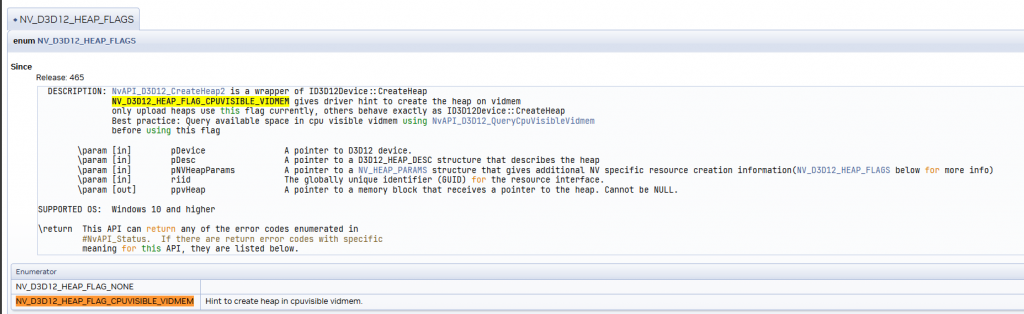
Using NVAPI it’s possible to create upload heap of CPU visible VRAM, basically making it possible to use DEVICE_LOCAL+HOST_VISIBLE heap from Vulkan. Newer D3D12 versions also have D3D12_HEAP_TYPE_GPU_UPLOAD, which should eliminate the need of using NVAPI.