While I’m experementing on making my execution environment for C++/C# interop I became curious about the performance of .NET 8 (under CoreCLR, not Mono). Maybe I can use it without Burst and transition via P/Invoke at all?
Test suite
Thankfully there’s already a test bench for Burst: https://github.com/nxrighthere/BurstBenchmarks
As we can see there, .NET Core 3.1’s RyuJIT is close enough to Burst, except for some heavy benchmarks like Pixar Raytracer:
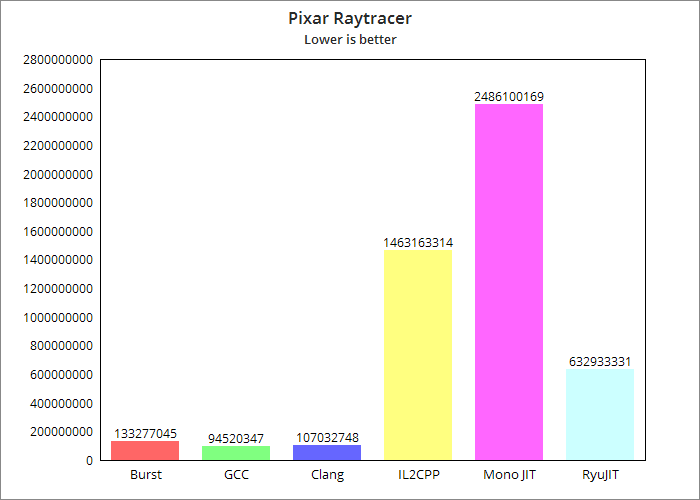
.NET 8 release notes state that there are many performance improvements. Should we test it?
Of course we should! In the process of the tests I’ve discovered that Burst is also improved quite a bit, but that’s not a topic for today.
I also won’t compare it with IL2CPP and MonoJIT because they are obvious outliers and GCC/Clang because it requires C++ compiling.
Testing environment: Ryzen 7 3700X Double-channel 2400x2 DDR4 RAM (2x16GB) Windows 11 22621.2338 Unity 2023.3.3f1 Burst 1.8.8 .NET 8.0.100-rc.1.23463.5
| Name / Ticks | Burst | .NET Core 3.1 | Ratio |
|---|---|---|---|
| Fibonacci | 54436007 | 59585552 | 0.91 |
| Mandelbrot | 18415897 | 23077983 | 0.80 |
| NBody | 58811032 | 76383602 | 0.76 |
| Sieve of Eratosthenes | 18915145 | 23110182 | 0.82 |
| Pixar Raytracer | 183511766 | 486419618 | 0.38 |
| Fireflies Flocking | 54675877 | 137409462 | 0.40 |
| Polynomials | 18634000 | 42546783 | 0.43 |
| Particle Kinematics | 51025754 | 125781180 | 0.40 |
| Arcfour | 87181726 | 103477418 | 0.84 |
| Seahash | 205824138 | 128275313 | 1.60 |
| Radix | 58589890 | 61706631 | 0.95 |
As we can see there, Burst is really faster in most of the cases, and it’s hard to average how much. In vectorized tests Burst shines and beats the soul out of .NET Core 3.1, but loosing badly in the tests with integer math (Seahash test)
Upgrading to .NET 8 (well, just switching the runtime version in Rider)
| Name / Ticks | Burst | .NET 8.0 | Burst Ratio | 3.1 Ratio |
|---|---|---|---|---|
| Fibonacci | 54436007 | 61106279 | 0.89 | 0.97 |
| Mandelbrot | 18415897 | 23280421 | 0.80 | 1.00 |
| NBody | 58811032 | 76712782 | 0.76 | 1.00 |
| Sieve of Eratosthenes | 18915145 | 32484755 | 0.58 | 0.71 |
| Pixar Raytracer | 183511766 | 120394846 | 1.52 | 4.00 |
| Fireflies Flocking | 54675877 | 111650793 | 0.48 | 1.23 |
| Polynomials | 18634000 | 26005384 | 0.71 | 1.63 |
| Particle Kinematics | 51025754 | 127686529 | 0.40 | 0.99 |
| Arcfour | 87181726 | 103320131 | 0.84 | 1.00 |
| Seahash | 205824138 | 127394971 | 1.60 | 1.00 |
| Radix | 58589890 | 60683769 | 0.95 | 1.00 |
.NET is greatly improved in float math heavy tests, with difficult branching, like Pixar Raytracer. It’s FOUR TIMES faster than .NET Core 3.1, and 1.5 times faster than Burst can provide.
At least we are not in the worse condition, except for Sieve of Eratosthenes. For some reason it’s 15-30% slower than .NET Core 3.1
Burst still shines where auto-vectorization is a big win, like particle kinematics.
But what if we give a little bit of hint for our JIT? Particle Kinematics test seems like an obvious case for SIMD, which is not automatically provided by RyuJIT yet.
// Original code
private struct Particle
{
// Note it's floats, not Vector3s/float3s
public float x, y, z, vx, vy, vz;
}
// ...
for (uint a = 0; a < iterations; ++a)
{
for (uint b = 0, c = quantity; b < c; ++b)
{
Particle* p = &particles[b];
p->x += p->vx;
p->y += p->vy;
p->z += p->vz;
}
}
First of all we will apply the most obvious correction, switch to SIMD-supported System.Numerics.Vector3
private struct Particle
{
public Vector3 pos, velocity;
}
// Corrected calculation code
...
for (uint a = 0; a < iterations; ++a)
{
for (uint b = 0, c = quantity; b < c; ++b)
{
Particle* p = &particles[b];
p->pos += p->velocity;
}
}
| Name / Ticks | Burst | .NET 8 With Help | Burst Ratio | .NET 8.0 Ratio |
|---|---|---|---|---|
| Particle Kinematics | 51025754 | 100510745 | 0.50 | 0.80 |
As we can see, this small change helps compiler a lot (20% faster than original .NET 8 version), but Burst is still twice as fast!
Machine-aligned vectors.
Since we are using Vector3 which is not aligned by machine’s 128-bit vector, let’s try to fix that and see if it helps.
private struct Particle
{
//replace Vector4 to float4 in Burst
public Vector4 pos, velocity;
}| Name / Ticks | Burst vec4 | .NET 8 vec4 | Burst Ratio | .NET 8.0 Ratio |
|---|---|---|---|---|
| Particle Kinematics | 30433174 | 42636315 | 0.71 | 0.33 |
As we can see, not only our code became three times faster compared to the original after JIT, but it’s also faster in comparison with Burst. Now it’s 30% slower than Burst optimized code.
Can we help .NET a little bit more?
for (uint a = 0; a < iterations; a++) // was ++a
{
Particle *pt = particles; // init pointer here
//for (uint b = 0, c = quantity; b < c; ++b)
// Remove c, don't confuse the JIT
for (uint b = 0; b < quantity; b++) // was ++b
{
//Particle* p = &particles[b];
pt->pos += pt->velocity;
pt++; // manually update pointer instead.
}
}
| Name / Ticks | Burst vec4 | .NET 8 vec4 | Burst Ratio | .NET 8.0 Ratio |
|---|---|---|---|---|
| Particle Kinematics | 30433174 | 32350603 | 0.94 | 0.25 |
Now we are only 5% slower than Burst.
A word on NativeAOT
In most of the tests NativeAOT show simillar performance to the JIT. The only profitable tests are Fibonacci (0.72x), Fireflies Flocking (0.80x) and Particle Kinematics after manual Vector3 addition give us glorious 0.66x ratio!
Conclusion
In my opinion, .NET 8’s JIT is mature enough to use in performance critical scenarios, given that it’s full .NET support, and not the subset like Burst (which allows it to produce faster code).
Much more mature than .NET 7, which is not shown there, but according to my tests, .NET 8 is much faster than .NET 7 on those same tests
Even when using JIT, and not AOT, it seems like an awesome environment to use!
But, you need to help your JIT
At least a little bit. It’s not yet capable of auto-vectorization, so in the scenarios where SIMD gives a huge help you’d better to use intrinsic Vector types from System.Numberics package.
A little sidenote on why Burst is faster in Vector3 scenario
// The code produced by .NET 8 with Vector3
vmovss xmm0, [r8+8]
vmovsd xmm1, [r8]
vshufps xmm1, xmm1, xmm0, 0x44
lea r10, [r8+0xc]
vmovss xmm0, [r10+8]
vmovsd xmm2, [r10]
vshufps xmm2, xmm2, xmm0, 0x44
vaddps xmm0, xmm1, xmm2
vmovsd [r8], xmm0
vpshufd xmm1, xmm0, 2
vmovss [r8+8], xmm1// The code produced by Burst
vmovsd xmm0, qword ptr [rdi]
vinsertps xmm0, xmm0, dword ptr [rdi + 8], 32
vmovsd xmm1, qword ptr [rdi + 12]
vinsertps xmm1, xmm1, dword ptr [rdi + 20], 32
vaddps xmm0, xmm1, xmm0
vmovlps qword ptr [rdi], xmm0
vextractps dword ptr [rdi + 8], xmm0, 2As we can see there, Not only Burst generates less code, but it’s also a little bit more clever. Instead of shuffling and having scalar movs, Burst just loads two Vector4s (instead of Vector3s), then add Vector4s together, and extracts Vector2 and one scalar to the position.
It’s totally possible to do in .NET, and according to my tests, it helps making it 20% faster than original generated code, but still not that fast as Burst gives us.
private struct Particle
{
public float x,y,z,w;
}
Particle *p = ;
float *f= (float*)p;
var myVec = new Vector4(f[0], f[1], f[2], f[3]);While it seems exactly like loading a Vector4 *(Vector4*)(p) this will absolutely kill your performance! JIT is not capable to understand that we are loading whole vector and loads it float by float.